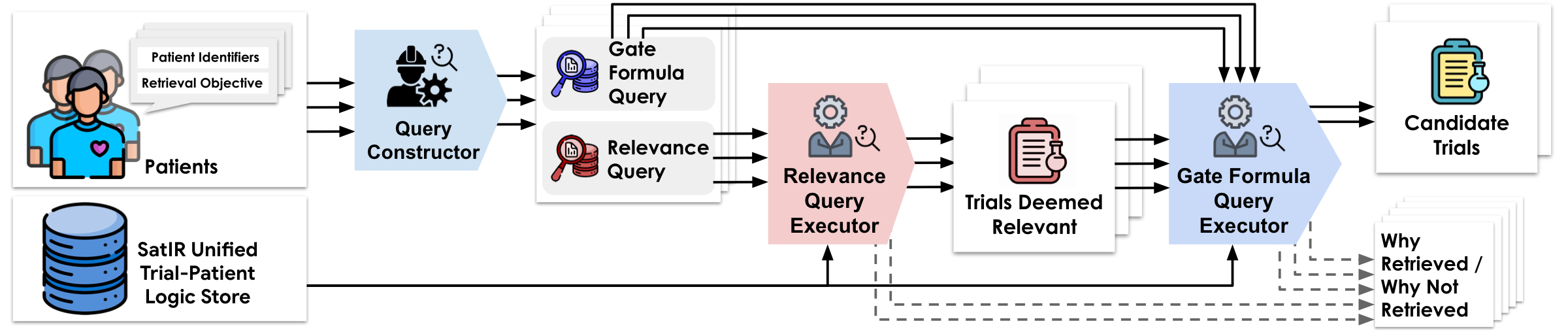
Constraint Execution
Constraint Execution is where SatIR runs patient constraints against the pre-built trial index. Two stages are involved: a high-recall SQL filter over stored CNF constraints, followed by LLM-based final matching on free text.
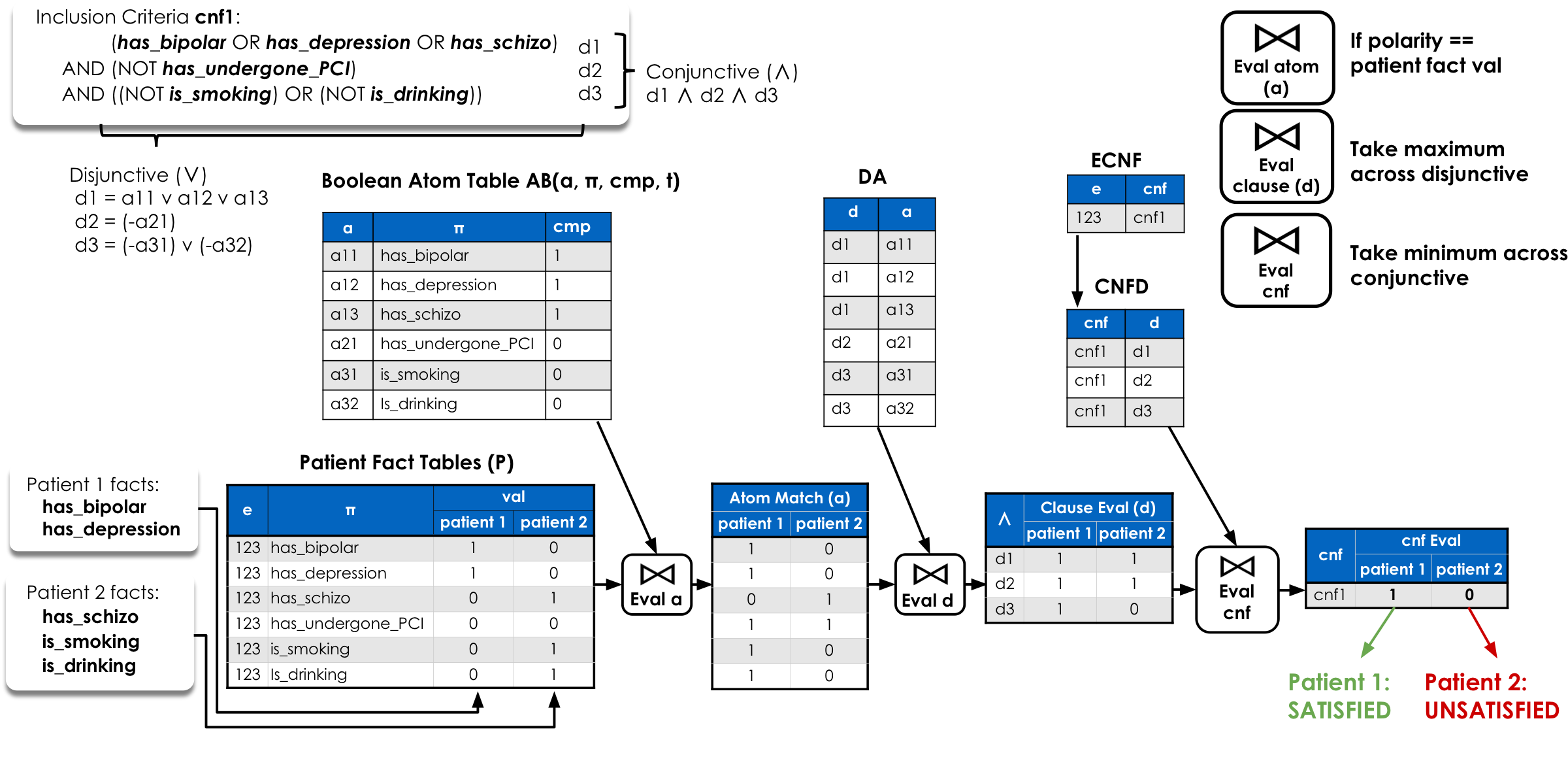
The objective θ filters which trial-side clauses are retrieval-relevant and which patient-side atoms may support them. A trial–patient pair (c, p) is returned only if every retrieval-relevant clause of c is supported — formally: ∀d ∈ Dθ(c), d is supported by p. Because salience alternatives are encoded as trial-side disjunctions in the stored CNF, whole-fact missingness and specificity uncertainty are handled by which branches can or cannot be satisfied — without expanding the patient side.
Atom level — compatible atom matching
Retrieval-relevant trial atoms and admissible patient atoms are joined on the same canonical predicate π and retained qualifier fields, requiring their comparison conditions to be mutually compatible. This yields a relation of compatible atom pairs (ac, ap).
Clause level — clause support
Compatible atom pairs are lifted through DA(d, a) to recover the trial clauses they fall under. A trial clause is marked supported if at least one of its member atoms has a compatible patient match — satisfying the clause's OR semantics.
CNF level — all-clause aggregation
Supported clauses are aggregated back through CNFD and ECNF. A trial–patient pair is returned only if the count of supported retrieval-relevant clauses equals the total — satisfying the CNF's AND semantics. Because projection is conservative, this layer may admit false positives but never eliminates a true match.
The LLM is never the sole arbiter. Its role is to resolve nuance in the residual candidate set that the formal system has already filtered for recall. All formal eligibility decisions remain auditable through the SMT layer; the LLM adds clinical interpretive power for the hard cases.
The natural-language matching procedure is decomposed into two stages:
Relevance identification
The LLM identifies all trial cohorts that are clinically relevant to the patient — without yet assessing eligibility. It returns a structured list of relevant cohorts with brief clinician-facing explanations. Many trials contain multiple arms or cohorts with different disease targets, so separating relevance from eligibility prevents conflating intent mismatch with failure of entry criteria.
Cohort-level eligibility assessment
For each relevant cohort, the LLM evaluates eligibility separately. It is instructed to apply clinical inference, project away operational and logistics-only requirements, reason only over current and past patient state, and apply explicit missingness rules when the record does not mention a required fact. Structured outputs at both stages make decisions auditable at the level of individual trial cohorts.